.png)
🟣 Enregistrer du code html avec Zennoposter - élément d'une balise DIV
#1 2021-10-06 08:08:21
- Mention Arthur_S
- 🥉 Grade : Scout


- Inscription : 2021-06-30
- Messages : 22
- Likes : 3
NetlinkingStratégie
Enregistrer du code html avec Zennoposter - élément d'une balise DIV
Bonjour à tous,
-
Voici plusieurs jours que je peine à enregistrer dans une liste du code html. @Seoxis m'ayant aidé, voici ce que j'arrive à faire et ne pas faire pour l'instant (en espérant que ça en aidera certain ![]() ).
).
-
Pour commencer, j'ai créé une action "Tabs > DOM" pour récupérer les informations de la page à l'aide d'une regex.
-
Puis, je suis allé dans l’examinateur du DOM 
-
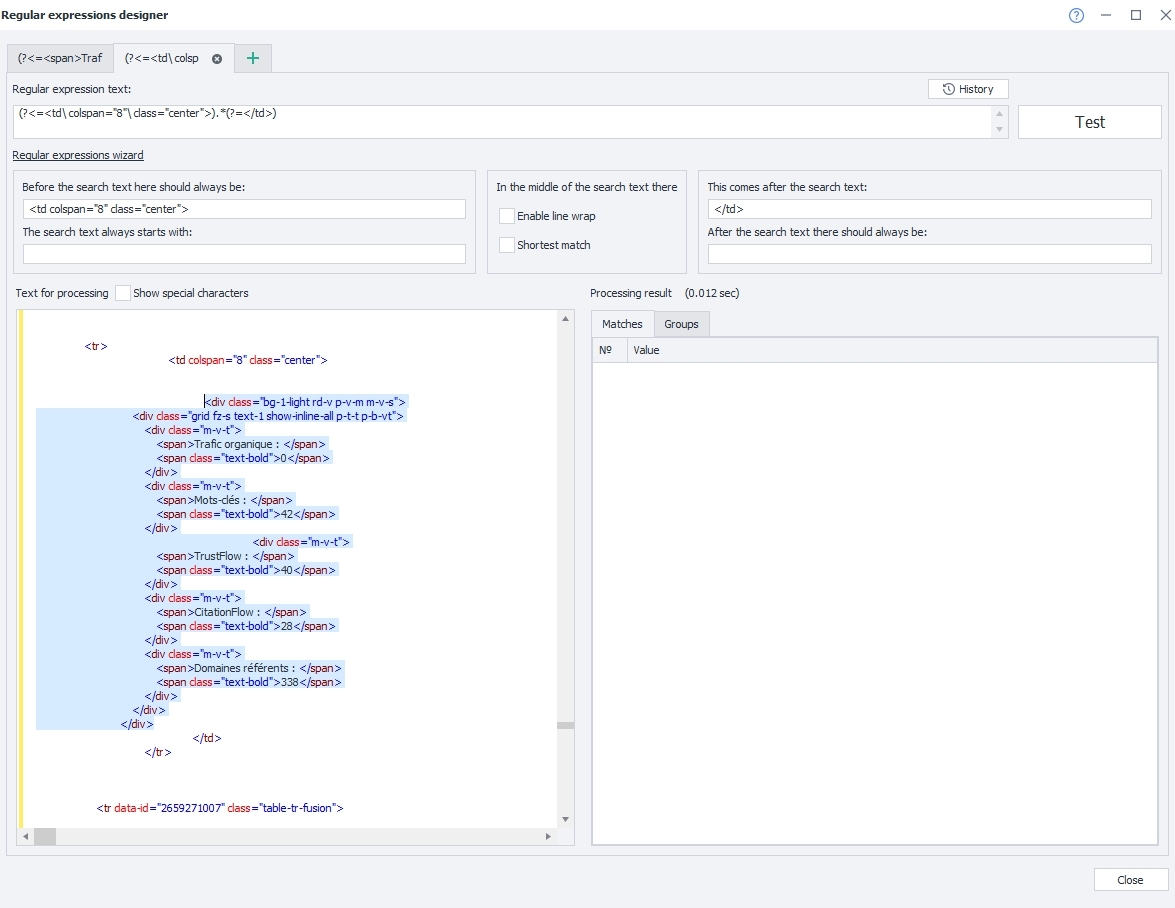
Et la j'ai essayé de créer ma regex. Le code ci-dessous sélectionnée en surbrillance est la balise DIV que j'essaie de récupérer (il y en a 9 autres dans la page).
-
-
<td colspan="8" class="center">
<div class="bg-1-light rd-v p-v-m m-v-s">
<div class="grid fz-s text-1 show-inline-all p-t-t p-b-vt">
<div class="m-v-t">
<span>Trafic organique : </span>
<span class="text-bold">97</span>
</div>
<div class="m-v-t">
<span>Mots-clés : </span>
<span class="text-bold">102</span>
</div>
<div class="m-v-t">
<span>TrustFlow : </span>
<span class="text-bold">35</span>
</div>
<div class="m-v-t">
<span>CitationFlow : </span>
<span class="text-bold">26</span>
</div>
<div class="m-v-t">
<span>Domaines référents : </span>
<span class="text-bold">89</span>
</div>
</div>
</div>
</td>
<div class="bg-1-light rd-v p-v-m m-v-s">
<div class="grid fz-s text-1 show-inline-all p-t-t p-b-vt">
<div class="m-v-t">
<span>Trafic organique : </span>
<span class="text-bold">97</span>
</div>
<div class="m-v-t">
<span>Mots-clés : </span>
<span class="text-bold">102</span>
</div>
<div class="m-v-t">
<span>TrustFlow : </span>
<span class="text-bold">35</span>
</div>
<div class="m-v-t">
<span>CitationFlow : </span>
<span class="text-bold">26</span>
</div>
<div class="m-v-t">
<span>Domaines référents : </span>
<span class="text-bold">89</span>
</div>
</div>
</div>
</td>
-
quand je clique sur le bouton "Test", il ne me retourne aucun résultat... ![]()
-
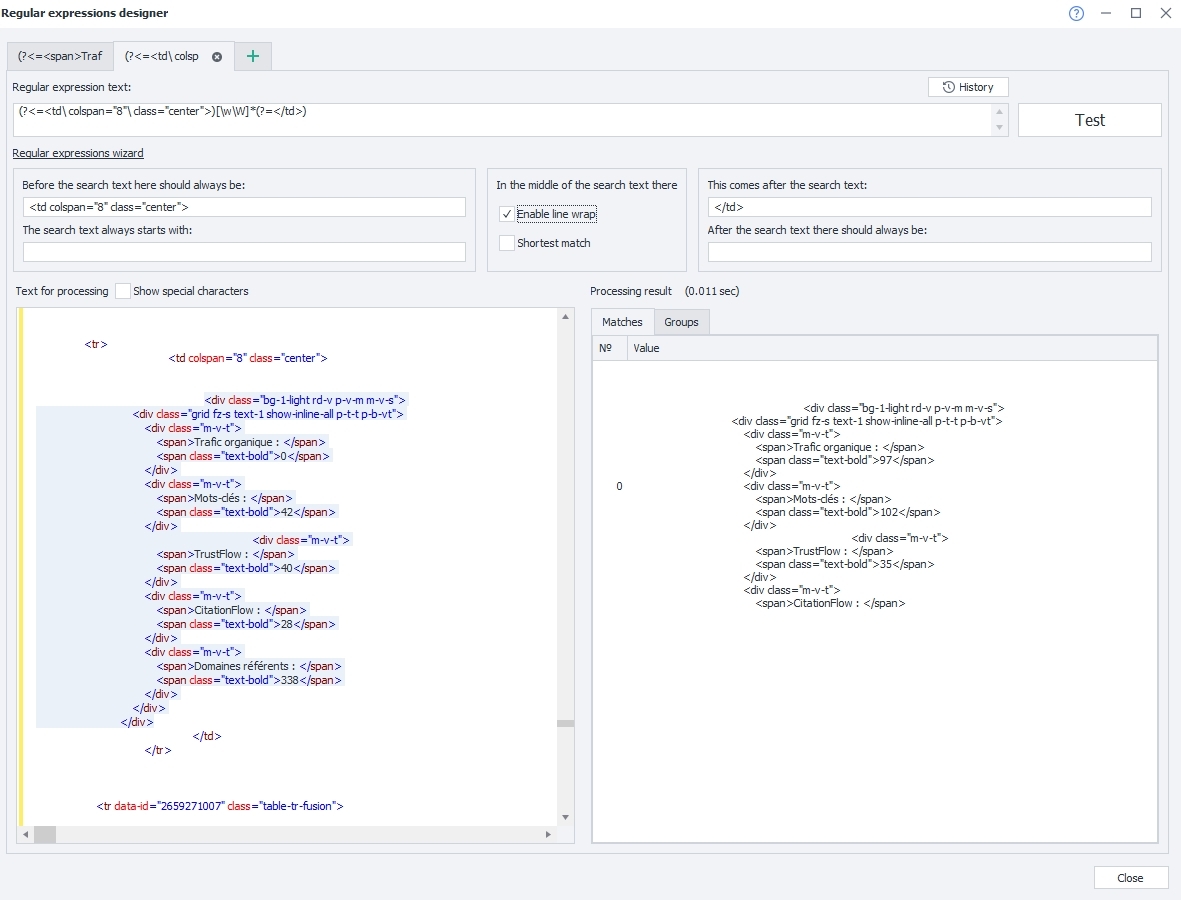
Le problème vient de la case "Enable line wrap" qu'il faut cocher parce que, et pour citer @Seoxis :
cocher la case "Enable line wap" pour prendre en compte le multi ligne (sinon les regex fonctionnent ligne par ligne)
On l'a cochant je n'obtient qu'un résultat :
-
-
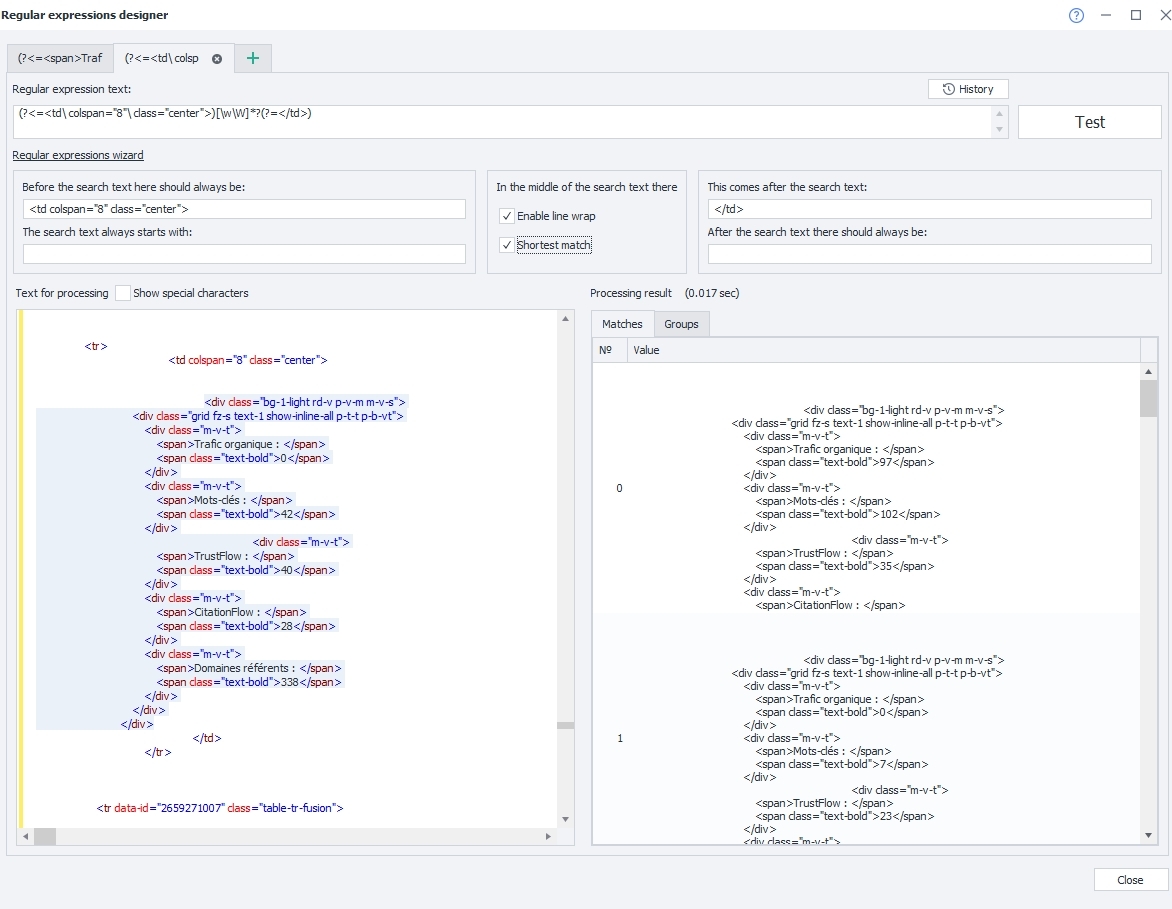
Il me faut aussi cocher la case "Shortest match" pour obtenir toutes les DIV de la page que je cherche à sauvegarder :
-
-
Voila, après il ne reste plus qu'à copier-coller votre regex pour l'ajouter à votre action "DOM" ![]() .
.
-
Ma nouvelle difficulté réside à partir de maintenant. Problème que j'expose ci-dessous dans ma prochaine réponse.
0
J'aime ❤️
🔴 Hors ligne
#2 2021-10-06 08:29:52
- Mention Arthur_S
- 🥉 Grade : Scout
- Inscription : 2021-06-30
- Messages : 22
- Likes : 3
NetlinkingStratégie
Re : Enregistrer du code html avec Zennoposter - élément d'une balise DIV
J'essaie maintenant de travailler les DIV que j'ai enregistré dans une liste grâce à l'action "DOM".
-
A l'aide de l'action "Data > Text processing > regex" je récupére la première ligne de ma liste pour y récupérer les informations qui m'intéresse. En premier, je veux sélectionner le "97" qui est le nombre de "Trafic organique".
<div class="m-v-t">
<span>Trafic organique : </span>
<span class="text-bold">97</span>
</div>
<span>Trafic organique : </span>
<span class="text-bold">97</span>
</div>

-
Je reviens donc sur la page de ZennoPoster qui permet de générer des regex. Et, je copie-colle le bout de code ci-dessous dans "Before the search text here should always be:" pour voir si j'arrive à récupérer le resultat souhaité :
<span>Trafic organique : </span>
<span class="text-bold">
<span class="text-bold">
Mais malheureusement, j'ai seulement le code ci-dessous qui s'affiche dans le champ :
<span>Trafic organique : </span>
J'ai essayé de cocher la case "Show special characters" et d'y ajouter ce qui s'affichait, mais sans succès :
-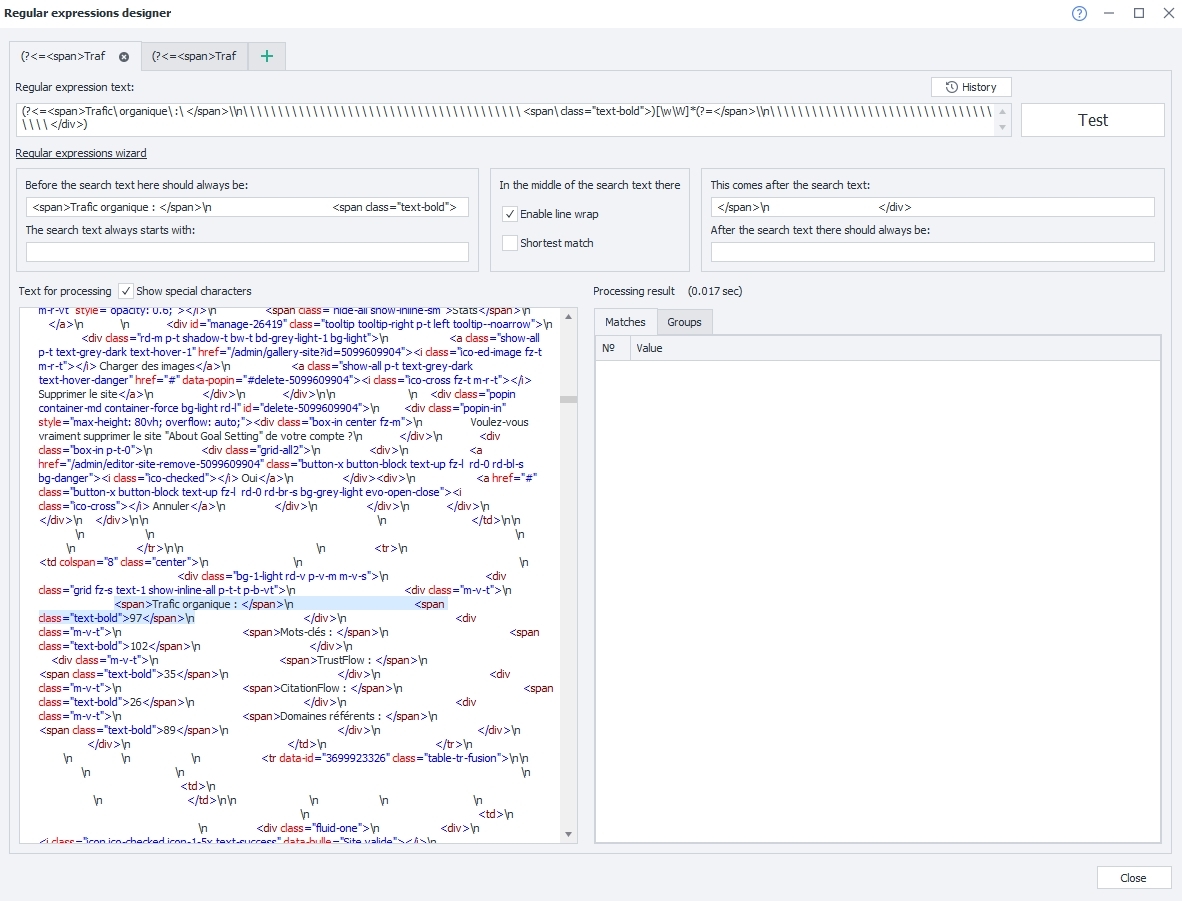
-
<div class="bg-1-light rd-v p-v-m m-v-s">\n <div class="grid fz-s text-1 show-inline-all p-t-t p-b-vt">\n <div class="m-v-t">\n <span>Trafic organique : </span>\n <span class="text-bold">97</span>\n </div>\n <div class="m-v-t">\n <span>Mots-clés : </span>\n <span class="text-bold">102</span>\n </div>\n <div class="m-v-t">\n <span>TrustFlow : </span>\n <span class="text-bold">35</span>\n </div>\n <div class="m-v-t">\n <span>CitationFlow : </span>\n <span class="text-bold">26</span>\n </div>\n <div class="m-v-t">\n <span>Domaines référents : </span>\n <span class="text-bold">89</span>\n </div>\n </div>\n </div>
Ma question est donc la suivante, comment faire pour que j'arrive à extraire le resultat "97" en utilisant les regex avec un code comme celui-ci ?
0
J'aime ❤️
🔴 Hors ligne
#3 2021-10-06 08:35:42

")
Re : Enregistrer du code html avec Zennoposter - élément d'une balise DIV
Before : <span class="text-bold">
After : </span>
Enable shortest Match.
Enregistre le tout depuis Text Processing sur une liste par exemple puis prend ligne par ligne pour utiliser tes données Majestic soit pour enregistrer ou autre...
_________
.
0
J'aime ❤️
🔴 Hors ligne
#4 2021-10-06 08:45:26
- Mention Arthur_S
- 🥉 Grade : Scout
- Inscription : 2021-06-30
- Messages : 22
- Likes : 3
NetlinkingStratégie
Re : Enregistrer du code html avec Zennoposter - élément d'une balise DIV
Merci pour ta réponse @Linuxma.
Le truc est que si je vais ça, je me retrouve aussi avec les résultats contenus dans les autres <span class="text-bold"> que contient la DIV.
0
J'aime ❤️
🔴 Hors ligne
#5 2021-10-06 09:00:39
Re : Enregistrer du code html avec Zennoposter - élément d'une balise DIV
Je pensais que tu avais déjà extrait la partie avec les metrics avant de process...
Je laisse la main à quelqu'un d'autre, je n'ai plus Zeno et je suppose que ça a bien changé depuis 2 ans.
_________
.
0
J'aime ❤️
🔴 Hors ligne
#6 2021-10-06 10:22:06
- Mention Arthur_S
- 🥉 Grade : Scout
- Inscription : 2021-06-30
- Messages : 22
- Likes : 3
NetlinkingStratégie
Re : Enregistrer du code html avec Zennoposter - élément d'une balise DIV
Je laisse la main à quelqu'un d'autre, je n'ai plus Zeno et je suppose que ça a bien changé depuis 2 ans.
![]() oui de ce que j'ai compris il y a eu des changements pour la V7
oui de ce que j'ai compris il y a eu des changements pour la V7
C'est bon, j'ai réussi à prendre la partie du code que je voulais. En fait, et comme l'avait précisé @Seoxis ![]() , il faut prendre en compte les espaces et retours à la ligne.
, il faut prendre en compte les espaces et retours à la ligne.
Dans un regex les espaces se matérialise par un \. Donc il faut mettre autant de \ qu'il y a d'espace. Le générateur de regex les ajoutent automatiquement si l'on copie-colle les espaces contenus entre les balises html du bout de code que l'on veut traiter .
Pour les retours à la ligne, l'expression est \n. La petite subtilité est qu'il faut l'ajouter à la main directement dans la regex qui est générée automatiquement (dans le champ : Regular expression text).
Ci-dessous l'image du générateur de regex. Notez que j'ai coché la "Show special characters" pour y voir plus clair. Si vous aussi vous avez coché cette case, pensez à enlever le \n que vous avez coller dans "Before search..." et de l'ajouter ensuite dans la regex générée.
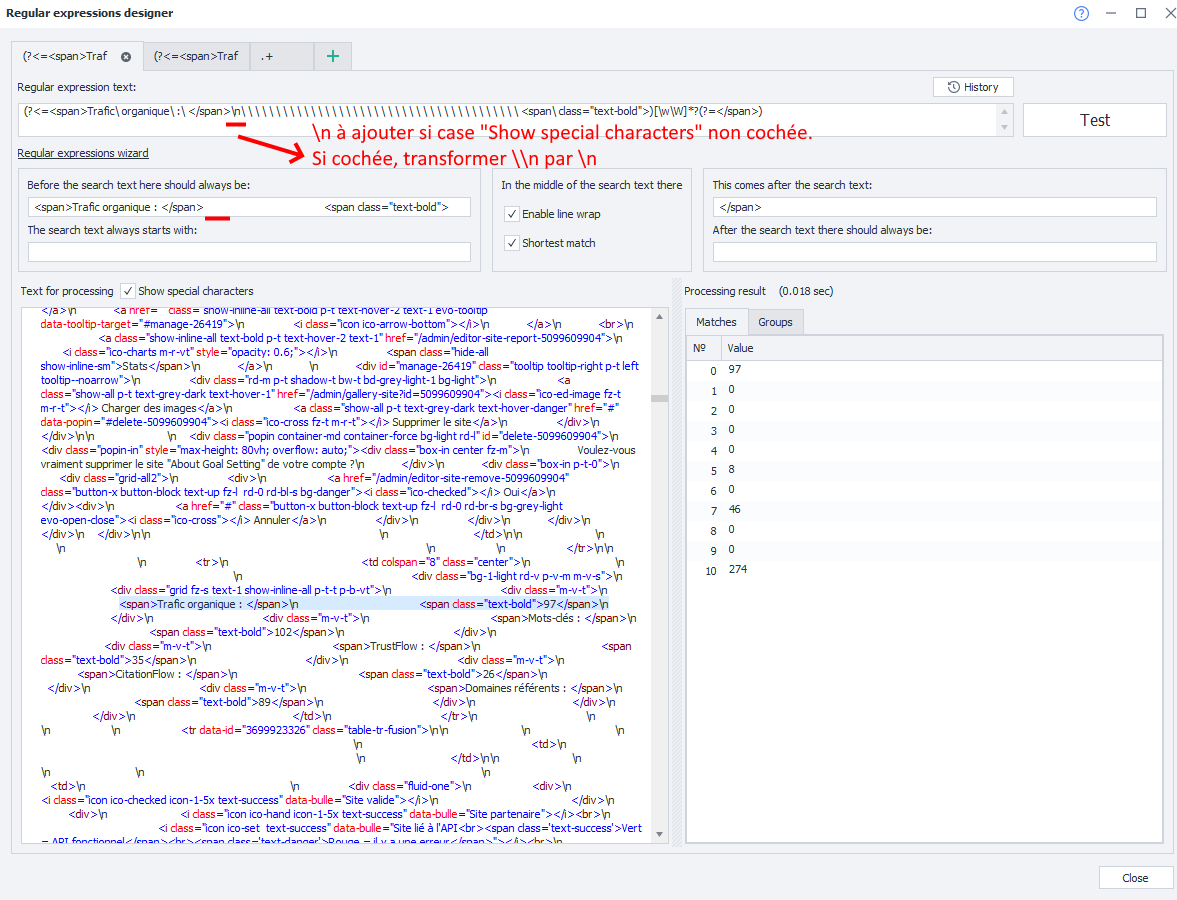
0
J'aime ❤️
🔴 Hors ligne
#7 2021-10-07 05:16:16
- Mention chn16000

- 🥉 Grade : Scout

")

")
")
- Inscription : 2017-04-07
- Messages : 1 913
- Likes : 165
MarketingAudit et AnalyseAutomatisation Web
Re : Enregistrer du code html avec Zennoposter - élément d'une balise DIV
Pas la bonne méthode car si il y a la moindre modif dans le nombre d'espace, ta regex risque de ne plus fonctionner.
Soyez vous-même, les autres sont déjà pris
0
J'aime ❤️
🔴 Hors ligne
#8 2021-10-07 10:03:03




")
Re : Enregistrer du code html avec Zennoposter - élément d'une balise DIV
chn16000 a écrit :
Pas la bonne méthode car si il y a la moindre modif dans le nombre d'espace, ta regex risque de ne plus fonctionner.
Malheureusement c'est la bonne méthode (avec les regex) même si ce n'est pas très safe sur le long terme mais pour la partie construction de regex c'est correct
ce qu'il faut retenir c'est que les regex c'est surtout utilisé pour extraire plusieurs données en 1x
ici la meilleur façon de faire serait d'extraire chaque div dans une liste et de travailler avec le code d'une seul div à la fois
il existe dans zenno plusieurs méthodes pour nettoyer ton code aussi (supprimer les espaces , saut de ligne pour épurer le code avant regex)
tu peux aussi transformer ton code html pour ne garder que la partie texte (ca va supprimer tout le code html inutile)
tu as aussi un outil sympa qui est le parse data (clic droit sur la donnée dans ton navigateur) qui te permet d'extraire toutes les données similaires dans une liste
A toi de dompter la bête mais déjà c'est top tu progresses , tu verras une fois l'outil en main c'est le jour et la nuit
Faut pratiquer : c'est en bûchant qu'on devient bûcheron ![]()
Enjoy !
Seoxis
Envie de me faire plaisir , achetez les mêmes proxys que j'utilise via ce lien : -=[ buyproxies.org ]=- (15€ pour 10 proxys dédiés)
Envie de tester ZennoPoster c'est par ici : -=[ ZennoPoster ]=- (à partir de 87$)
0
J'aime ❤️
🔴 Hors ligne
#9 2021-10-07 18:54:00
- Mention chn16000
- 🥉 Grade : Scout
- Inscription : 2017-04-07
- Messages : 1 913
- Likes : 165
MarketingAudit et AnalyseAutomatisation Web
Re : Enregistrer du code html avec Zennoposter - élément d'une balise DIV
Je me suis mal exprimé. La regex est la bonne méthode mais sa regex risque de ne pas fonctionner longtemps amha.
Soyez vous-même, les autres sont déjà pris
0
J'aime ❤️
🔴 Hors ligne