
Pages :: 1
🟣 Markovify : générer du texte thématique
#1 2019-12-10 07:52:41
- Mention NicolasWeb

- 🥉 Grade : Scout


")

- Lieu : Besançon (France)
- Inscription : 2015-09-30
- Messages : 1 114
- Likes : 214
RédactionSémantique- Site Web
Markovify : générer du texte thématique
Voici un sujet pour parler de la librairie Python Markovify : hxxps://github.com/jsvine/markovify
Comme son nom le suggère, il s'agit d'une librairie de fonctions qui vont nous permettre de manipuler des chaînes de Markov.
Je cite Wikipedia :
En mathématiques, une chaîne de Markov est un processus de Markov à temps discret, ou à temps continu et à espace d'états discret. Un processus de Markov est un processus stochastique possédant la propriété de Markov : l'information utile pour la prédiction du futur est entièrement contenue dans l'état présent du processus et n'est pas dépendante des états antérieurs (le système n'a pas de « mémoire »). Les processus de Markov portent le nom de leur inventeur, Andreï Markov.
Vous n'y comprenez rien ? C'est pas grave, ce qu'il faut comprendre c'est que c'est utile pour prédire le futur en fonction d'une information actuelle (oui rien que ça ! ).
Cela se passe sur un système de probabilité si j'ai bien compris...
Enfin, passons à ce qui nous intéresse dans notre cas : comment générer un texte aléatoire thématique à partir de cet outil et des chaînes de Markov ?
Tout d'abord, pour faire fonctionner l'outil, il est nécessaire d'avoir deux choses :
1/ des connaissances en programmation Python
2/ un grand nombre de textes thématique
Le texte est ce qu'on appelle un corpus, il va servir au logiciel pour qu'il prenne connaissance de la thématique. Donc, plus il est important et plus cela va fonctionner correctement.
Pour mes besoins, je récupère des textes provenant de vieux livres disponibles en ebook ou sur archive.org.
Je ne conserve que les phrases correctement formées qui commencent par une majuscule et se termine par un point. C'est très important de procéder comme cela pour que cela fonctionne au mieux.
Ensuite, l'usage est assez simple :
# -*- coding: utf-8 -*-
# python 3
# Générer un texte à partir d'une chaîne de Markov
import markovify
# Chargement du fichier
with open("economie.txt", encoding='utf-8') as f:
text = f.read()
model = markovify.Text(text)
# On affiche cinquante phrase
for i in range(50):
print(model.make_sentence())
"""
# On peut définir une contrainte sur la taille du texte
for i in range(3):
print(model.make_short_sentence(280))
"""
Comme vous pouvez le constater, j'ai utilisé un de mes fichiers qui parle d'économie en général (economie.txt).
Voici un exemple de résultat :
Une meilleure vision de son entreprise une démarche d’intelligence économique.
Votre cible principale sera souvent l'elu ou la technologie est l'un des volets de la confidentialité des données informatiques vers une démarche adaptée et c’est bien le premier pas vers une société extérieure spécialise dans la societe française dans les échanges sont de plus en plus intense qui caractérise notre époque.
Dans ce contexte, notre démarche de veille trop large ; établissez des priorités de la nécessité de protéger au mieux ses innovations : elle a lance début 2010 « IE Sante », un programme d’actions collectives et faire nos preuves sur les ordinateurs dont les entreprises et les accompagne dans leurs secteurs, se développent et réalisent des acquisitions hors de France.
Les services de l’État et pour le secteur aéronautique.
Identifiez les documents a remettre aux visiteurs afin d’éviter de laisser un document qui pourrait lui être reproche dans le cadre d’une procédure contentieuse initiée par un concurrent étranger : dans un endroit sur.
Tracfin est la pérennisation d’une démarche d’intelligence économique sont en perpétuelle évolution, notamment pour tout ce qui pourrait contenir des informations stratégiques.
A l'échelle d’une PME, cette démarche doit être fait par une phase de développement et d’innovation des TPE-PME, depuis la balance des comptes et d’en coordonner la mise en place d’un espion informatique dans un monde multipolaire, qu'une simple veille sectorielle ne suffit pas de remercier et d’exprimer votre reconnaissance aux élus et aux accords de consortium entre grands groupes, PME et centres de recherche.
Le texte est plutôt correct pour du T2 ou du T3. En tout cas, c'est l'usage que j'en fait.
Maintenant, ce qui est très important à comprendre, c'est que la quantité de texte que vous lui ferez "apprendre" doit être énorme pour obtenir un résultat comme le mien.
Dans le cas du fichier que j'ai utilisé, on est sur une base de plus de 40 000 mots. Donc, c'est pour cela que j'utilise surtout des livres du domaine public pour générer des textes à partir d'une chaîne de Markov.
Si vous n'arrivez pas à avoir une quantité de texte suffisante, le résultat sera vraiment pas bon...
0
J'aime ❤️
🔴 Hors ligne
#2 2019-12-10 09:00:35


")

Re : Markovify : générer du texte thématique
Merci c'est top !
Pour ceux qui codent en nodeJS il y a aussi des packages npm ![]()
Est-ce que tu aurais une quantité de mots minimale pour ton corpus à conseiller pour avoir un résultat "potable" ?
@ + !
==> Besoin d'une presta netlinking ? DM <==
0
J'aime ❤️
🔴 Hors ligne
#3 2019-12-10 09:05:53
- Mention NicolasWeb
- 🥉 Grade : Scout
- Lieu : Besançon (France)
- Inscription : 2015-09-30
- Messages : 1 114
- Likes : 214
RédactionSémantique- Site Web
Re : Markovify : générer du texte thématique
nod_ a écrit :
Merci c'est top !
Pour ceux qui codent en nodeJS il y a aussi des packages npm
Est-ce que tu aurais une quantité de mots minimale pour ton corpus à conseiller pour avoir un résultat "potable" ?
@ + !
Je trouve qu'autour de 30 000 c'est pas mal.
Il faut aussi que les phrases soient bien différentes.
Pour un résultat optimal, je dirais que 100 000 c'est bien...
0
J'aime ❤️
🔴 Hors ligne
#4 2019-12-10 09:28:55
- Mention poulpe_centriste

- 🥉 Grade : Scout
- Inscription : 2018-07-03
- Messages : 573
- Likes : 173
Re : Markovify : générer du texte thématique
J'ai commencé aussi il y a quelques semaines à utiliser markovify et je confirme, c'est sympa. Tests en cours
Perso, à moins de faire du pr0n (les gens sont plus occupés à se palucher que de lire ton essai sur les 10 meilleurs plans cougar à Belfort), je ne mettrai pas de bouillie markovifiée sur une page destinée aux humains.
Pour ce qui est du corpus, je ne me prends pas trop la tête. Le contenu est destiné aux robots donc RAB que les phrase soient lisibles. Tu créées ton corpus à partir de la SERP <20 (qui contient à priori les ngrammes intéressants), tu vires le boilerplate et voilà.
Dans l'histoire, le plus chronophage c'est la pipeline pour une mise en forme naturelle du contenu, liens compris.
D'ailleurs pour les images y'a plein de choses à faire histoire de montrer à Google qu'une page possède des images uniques (via les librairies d'image to image translation ou de generative model).
SinGAN semble prometteur: https://github.com/tamarott/SinGAN
0
J'aime ❤️
🔴 Hors ligne
#5 2019-12-10 09:45:03

")
")
")
#6 2019-12-10 13:40:03
Re : Markovify : générer du texte thématique
NicolasWeb a écrit :
Je trouve qu'autour de 30 000 c'est pas mal.
Il faut aussi que les phrases soient bien différentes.Pour un résultat optimal, je dirais que 100 000 c'est bien...
Top merci pour l'info, intéressant si on veut du contenu lisible par des humains.
poulpe_centriste a écrit :
J'ai commencé aussi il y a quelques semaines à utiliser markovify et je confirme, c'est sympa. Tests en cours
Pour ce qui est du corpus, je ne me prends pas trop la tête. Le contenu est destiné aux robots donc RAB que les phrase soient lisibles. Tu créées ton corpus à partir de la SERP <20 (qui contient à priori les ngrammes intéressants), tu vires le boilerplate et voilà.
Yop , je suis aussi dans l'optique de générer uniquement pour le robot google.
Voici le résultat d'un test obtenu par pure bouillie - récup de contenu sur google et mélange aléatoire de toutes les phrase + mots : du bien bien déguelasse donc, je confirme que les textes n'ont absolument aucun sens. Quelques H2/H3 dans le texte avec le KW, pas d'image.
Test lancé il y a même pas 5 jours :
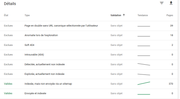
Toutes mes URLs se sont indexées (j'ai généré 380 pages pour ce test). On observe cependant un petit soucis de duplicate.
Et pour les stats :

A suivre donc, mais je me pose justement l'intérêt d'intégrer Markov dans mon algo.
Est-ce que vous avez pu observer des différences au niveau de l'indexation et du ranking avec et sans markov ?
Au niveau du duplicate je pense que ça peut surement aider.
Je précise que dans mon cas la lisibilité du texte par un humain ne m'importe pas.
@ + !
==> Besoin d'une presta netlinking ? DM <==
0
J'aime ❤️
🔴 Hors ligne
#7 2019-12-10 14:47:56
- Mention poulpe_centriste
- 🥉 Grade : Scout
- Inscription : 2018-07-03
- Messages : 573
- Likes : 173
Re : Markovify : générer du texte thématique
nod_ a écrit :
Toutes mes URLs se sont indexées (j'ai généré 380 pages pour ce test). On observe cependant un petit soucis de duplicate.
On est d'accord que ce sont 380 pages issues de 380 corpus différents ? Après ça vaut peut être le coup de passer un coup de https://github.com/seomoz/simhash-py en interne et externe?
Peut être qu'effectivement, si le corpus de base est trop pauvre (toutes sources utilisent un langage peu varié, hors ngrammes intéressants pour la requête), tu te retrouves forcément à tourner en rond dans tes chaines de markov.
Donc peut être qu'un coup de Spacy pourrait t'éclairer sur la richesse du corpus de base. Genre si ton corpus se compose principalement de fiches produit, ça risque d'être pauvre. Donc le duplicate vient aussi peut-être de la source.
De mon côté (en anglais sur un expiré, même théma), j'attends encore un peu mais ça n'a pas l'air de repartir à cause du domaine, pas du contenu.
0
J'aime ❤️
🔴 Hors ligne
#8 2019-12-10 16:58:07
Re : Markovify : générer du texte thématique
poulpe_centriste a écrit :
nod_ a écrit :Toutes mes URLs se sont indexées (j'ai généré 380 pages pour ce test). On observe cependant un petit soucis de duplicate.
On est d'accord que ce sont 380 pages issues de 380 corpus différents ? Après ça vaut peut être le coup de passer un coup de https://github.com/seomoz/simhash-py en interne et externe?
Peut être qu'effectivement, si le corpus de base est trop pauvre (toutes sources utilisent un langage peu varié, hors ngrammes intéressants pour la requête), tu te retrouves forcément à tourner en rond dans tes chaines de markov.
Donc peut être qu'un coup de Spacy pourrait t'éclairer sur la richesse du corpus de base. Genre si ton corpus se compose principalement de fiches produit, ça risque d'être pauvre. Donc le duplicate vient aussi peut-être de la source.
De mon côté (en anglais sur un expiré, même théma), j'attends encore un peu mais ça n'a pas l'air de repartir à cause du domaine, pas du contenu.
Sympa Spacy je ne connaissais pas !
Je ne sais pas si j'ai été clair mais en fait je n'utilise pas Makrov dans mon algo actuel : je génère un corpus : 1 page = bouillie totale du top 100 google (recup de phrases et melange completement aleatoire des mots ). Du coup oui mon corpus peut être assez similaire pour deux requêtes si les résultats retournés (top 100) sont similaires. D'ou le soucis je suppose, effectivement.
Je me demandais donc si intégrer Markov à un algo de génération de bouillie avait des chances d'améliorer l'indexation / ranking par rapport à de la bouillie pure (qui a l'air de fonctionner pour l'instant d'après mon test).
@ + ![]() !
!
==> Besoin d'une presta netlinking ? DM <==
0
J'aime ❤️
🔴 Hors ligne
#9 2019-12-10 16:58:24
- Mention NicolasWeb
- 🥉 Grade : Scout
- Lieu : Besançon (France)
- Inscription : 2015-09-30
- Messages : 1 114
- Likes : 214
RédactionSémantique- Site Web
Re : Markovify : générer du texte thématique
nod_ a écrit :
Est-ce que vous avez pu observer des différences au niveau de l'indexation et du ranking avec et sans markov ?
Mon expérience (non scientifique, c'est plus du ressenti ou de la superstition) est la suivante :
Pour du Money Site, clairement Markov si lisible par un humain.
Pour du Tier 2 : si on travaille sur une requête avec beaucoup de recherches le markov tient mieux dans le temps que la bouillie. Si on travaille sur une requête de faible intérêt / peu de recherche, alors tout tient plutôt bien. J'ai même de la pure bouillie en place depuis 2 ans sans soucis et ça envoie du jus...
Pour du Tier 3 : je met n'importe quoi, de la bouille, des suites de mots, etc.
Après, je le répète : ce n'est pas scientifique. Mais si j'ai le choix entre Markov et bouillie, je préfère maintenant passer 3h de plus sur le corpus et envoyer du Markov ![]()
0
J'aime ❤️
🔴 Hors ligne
#10 2019-12-10 17:00:11
Re : Markovify : générer du texte thématique
NicolasWeb a écrit :
nod_ a écrit :Est-ce que vous avez pu observer des différences au niveau de l'indexation et du ranking avec et sans markov ?
Mon expérience (non scientifique, c'est plus du ressenti ou de la superstition) est la suivante :
Pour du Money Site, clairement Markov si lisible par un humain.
Pour du Tier 2 : si on travaille sur une requête avec beaucoup de recherches le markov tient mieux dans le temps que la bouillie. Si on travaille sur une requête de faible intérêt / peu de recherche, alors tout tient plutôt bien. J'ai même de la pure bouillie en place depuis 2 ans sans soucis et ça envoie du jus...
Pour du Tier 3 : je met n'importe quoi, de la bouille, des suites de mots, etc.Après, je le répète : ce n'est pas scientifique. Mais si j'ai le choix entre Markov et bouillie, je préfère maintenant passer 3h de plus sur le corpus et envoyer du Markov
Super, merci pour ton retour. Markov avec les libs existantes n'a pas l'air fastidieux à mettre en place, je vais tester ça du coup ![]()
==> Besoin d'une presta netlinking ? DM <==
0
J'aime ❤️
🔴 Hors ligne
Pages :: 1