.png)
🟣 Introduction aux bases de fonctionnement d'indexation thématique
#1 2013-04-24 08:40:13
- Mention Abysse
- 🥉 Grade : Scout

- Inscription : 2013-04-20
- Messages : 110
- Likes : 0
Introduction aux bases de fonctionnement d'indexation thématique
Bien je vais essayer de faire assez court, c'est un sujet massif!
Pour ceux qui démarrent le SEO, c'est un post qui à mon sens est incontournable pour bien cerner comment marche Google!
LE CONSTAT / PROBLEMATIQUE
Google indexe des sites et classe les résultats par thématique! Comment Fait-il?
EXPLICATIONS
En fait Google ne lit pas un texte d'une façon littérale et n'a pas la moindre idée de ce que vous déblatérez!
Prenons l'exemple de cette phrase unique
de prenons unique l' phrase de exemple
Pour Google cela a presque le même sens à qq nuances prêt.
Ce qui importe à Google ce sont les concepts sémantiques, les concepts liants et le tout répartis par groupes ngrams.
En clair, Google fonctionne par mots clefs principaux qui définissent une thématique, les mots clefs reliés et qui nuancent le sens de la thématique et qui peuvent relier d'autres thèmes principaux/connexes. Ces thèmes sont analysés par groupe de 8 mots (ngrams).
NB : le nombre de mots par ngram n'a pas été révélé par Google mais par Bing. On imagine que c'est assez voisin.
NB 2 : Les concepts principaux sont définis par occurrences (répétition naturelle) et les concepts liants renforçant la thématique principale.
Bref, Google fait une carte sémantique d'un texte et donne de l'importance aux concepts principaux. Voici un exemple:
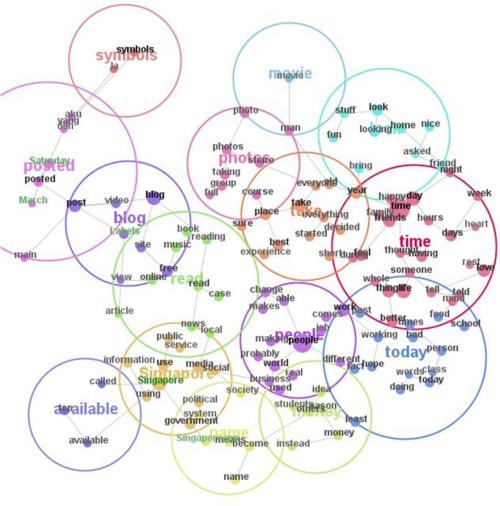
Ce type de carte peuvent être donner par un logiciel tel que Leximancer. Dommage par contre que le HTML ne soit pas exclut.
Webmaster tools affiche les concepts aussi d'un site pour vous donner une idée de ce que Google voit.
Bien maintenant que Google sait de quoi parle votre site, il va utiliser tous les facteurs possibles pour essayer de comprendre encore mieux. D'où les ancres des sites externes et probablement la thématique du site autour du lien. Vous comprendrez aussi que Google va pondérer en fonction des critères, des types de liens, le poids et l'impact sémantique d'un site sur un autre.
Voili voilou, pour la base des bases, par contre sachez qu'une énorme inconnue est présente. Google indexe des milliards de pages depuis près de 20 ans. Les données et les statistiques récoltées sont colossales et leur exploitation reste inconnue. ![]()
Dernière modification par Abysse (2013-04-24 08:53:12)
0
J'aime ❤️
🔴 Hors ligne
#2 2013-04-24 08:42:48
- Mention Abysse
- 🥉 Grade : Scout
- Inscription : 2013-04-20
- Messages : 110
- Likes : 0
Re : Introduction aux bases de fonctionnement d'indexation thématique
Ah oui, petite ommission!
Google a une liste de mots appelés stop words! Ce sont des mots qui ne sont pas indexés et ne changent rien à la map sémantique.
Il sont très facilement identifiable en copiant/collant une phrase indexée dans google et en regardant les mots qui ne sont pas en gras
Voici la liste des stops words anglais :
0
J'aime ❤️
🔴 Hors ligne
#3 2013-04-24 10:21:41
- Mention Pilone38
- 🥉 Grade : Scout
- Lieu : Isère
- Inscription : 2013-02-25
- Messages : 126
- Likes : 3
Re : Introduction aux bases de fonctionnement d'indexation thématique
Sympa Abysse ces précision, cela peut rafraichir la mémoire à pas mal de monde. Quel est ton avis sur le pouvoir de référencement de liens sur du contenu non fr pour positionner une page en fr, disons sur un mot clé pas trop trop concurrentiel ?
Tous les avis m'intéresse. Je suis septique encore sur ce sujet.
0
J'aime ❤️
🔴 Hors ligne
#4 2013-04-24 10:27:56
- Mention Abysse
- 🥉 Grade : Scout
- Inscription : 2013-04-20
- Messages : 110
- Likes : 0
Re : Introduction aux bases de fonctionnement d'indexation thématique
Grande question à laquelle j'ai peur de dire des bêtises.
Si les liens sont issus de site non FR, mais que le contenu est en FR, le pouvoir est grand.
Dans le cas contraire avec du contenu anglais sur site anglais avec une ancre française, attention a penguin
Enfin cela reste non testé, et mon avis perso.
0
J'aime ❤️
🔴 Hors ligne